The art of tokenization
Tokenization is the process of breaking down a text into smaller units called tokens. These tokens are the basic building blocks of language models. The tokens are then converted into embeddings, which are vectors that represent the tokens in a high-dimensional space. The embeddings capture the semantic and syntactic properties of the tokens, allowing the language model to learn the relationships between them.
Tokens are fundamental building blocks of LLMs. The way we do tokenization can have a huge effect on the LLM output.
The big picture where tokenization sits in the language model
There are many algorithms to tokenize. The following diagram gives a sneak peak into where the tokenization sits in the overall process of creating a language model. This is the schematic diagram of word2vec method to do token embedding.
This is a fast forward of the future processes, after tokenization.

Text can be broken down into the following units -
Disadvantage of character based tokenization
- This will make the number of tokens very large. The big paragraphs cannot fit into context length.
- This way we we would be destroying the structure of language. word drive similar meaning when they are grouped together. The indirect way to drive #semantics_will_be_destroyed.
- vocabulary size will be small. it will solve the OOV problem.
- ballooning effect - context window - amount of text LLM can pay attention in one time. high number of tokens will lead to reduced context window, as it will hit the upper limit of context window. measuring of context window is always with respect to number of tokens, and not number of bytes.
Disadvantage of word based tokenization
-
learn, learning, learned, learnt - all are different tokens. But they are similar in meaning. Having them as separate tokens does not help. This leads to large vocabulary size. More than 1 million English words.
For every word in the vocabulary, the logits metrics will give a matrix with number of column same as vocab size. So, next token prediction task will become slow and it will take up more space. -
Also, the word based tokenization will not be able to identify the tokens if there are grammatical errors, spelling errors. And that will lead to out of vocabulary (OOV) error.
Sub-word based tokenization
- Solves all the above issues. Eg : BPE - Byte pair encoding.
- Used in GPT-2, GPT-4, Llama2, BERT, etc.
BPE - Byte Pair Encoding - Building up the embeddings from sub-words
Typically the tokenization is done for sub-words using a technique like say BPE (Byte Pair Encoding). The vocabulary is then converted into embeddings. These sub-words embedding can then be averaged out to create word level embeddings or sentence level embedding.
Typically tokenization is done on sub-words level, and then the embeddings are rolled up to higher abstract levels based on the need.
value of k
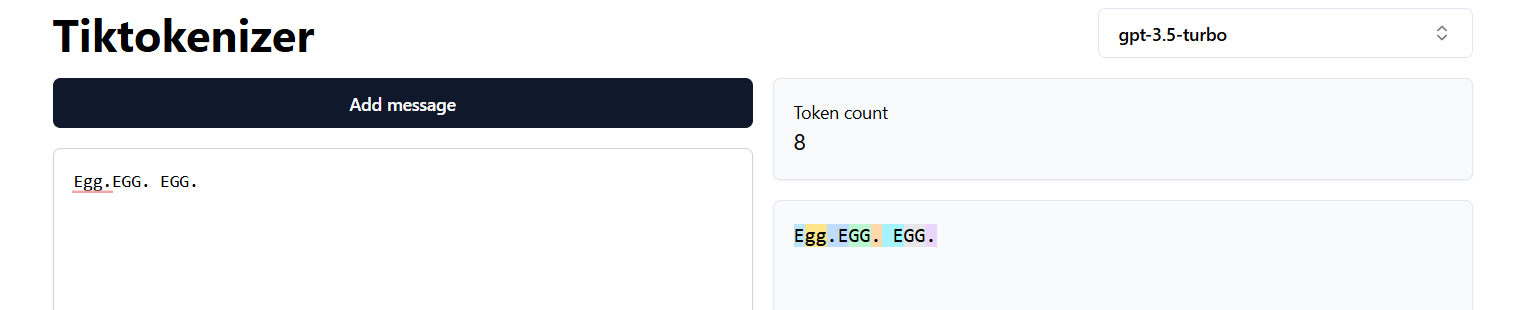
Differences in tokenizations across 4o and 3.5
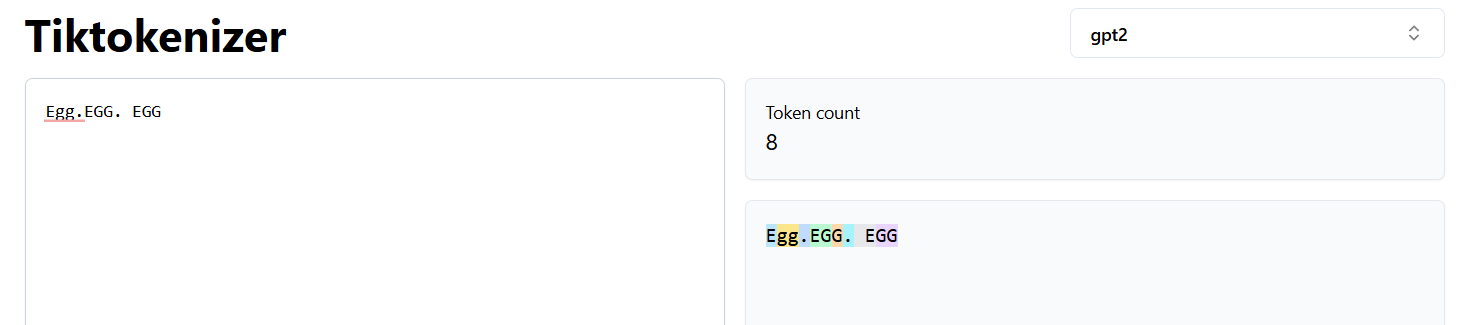
Tokenization in gpt2
Tokenization in gpt3.5
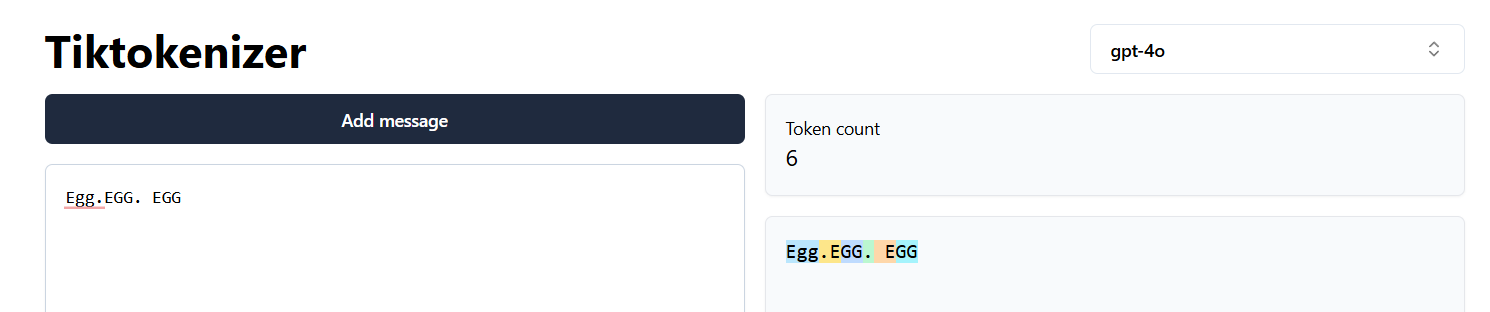
Tokenization in gpt4o
Tokenization in gpt4o - multi-lingual
मेरे प्रधानमंत्री नरेंद्र मोदी हैं।
When language is not trained, then every characters are taken as a separate tokens. so gpt2 has more tokens. gpt4o has less tokens because it was trained in different languages. multi-lingual data were used for training gpt4o. Hence number of tokens in gpt4o is lesser than gpt3.5 or gpt2.
While tokenizing the text in say, BPE, the higher the training data, the more the possibility of merging common tokens, leading to fewer overall tokens for a given text. This is because BPE iteratively merges the most frequent sub-word pairs, and with more data, frequently occurring sub-words (such as root words) tend to be retained as single tokens rather than being broken down further into smaller units or even characters.
Although BPE does not capture semantics, a larger and more diverse training corpus indirectly optimizes tokenization by ensuring that meaningful sub-words and root words remain intact as larger token units; instead of being broken down further. This leads to lower overall tokens.
So, the learning corpus is important to ensure that the lesser tokens are formed, and more meaningful tokens are retained.
Lesser numbers of tokens are identified, more accurate would be the model.
GPT4o tokenization of Hindi - 6 tokens
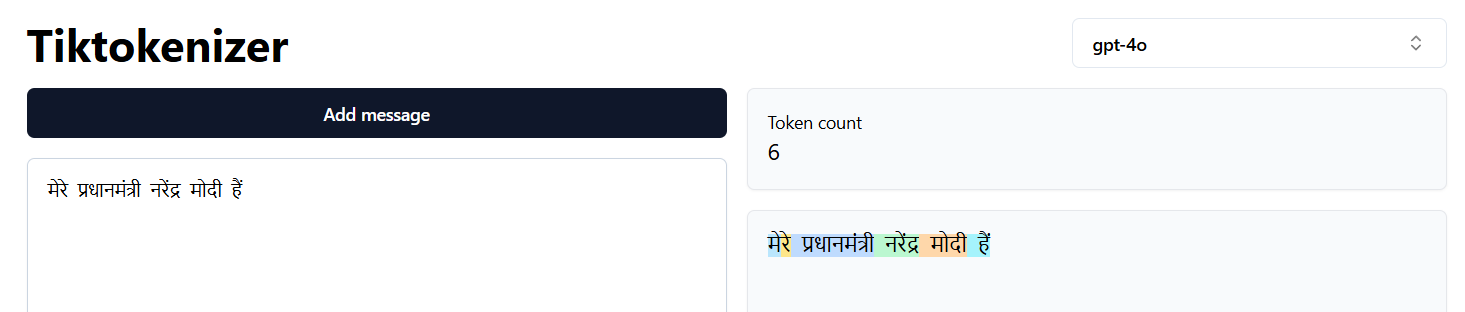
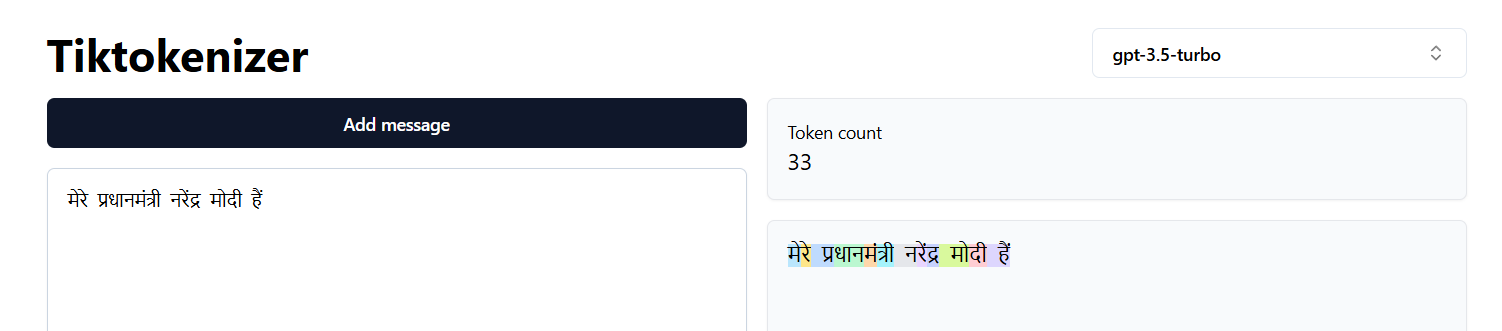
GPT3.5 tokenization of Hindi - 33 tokens
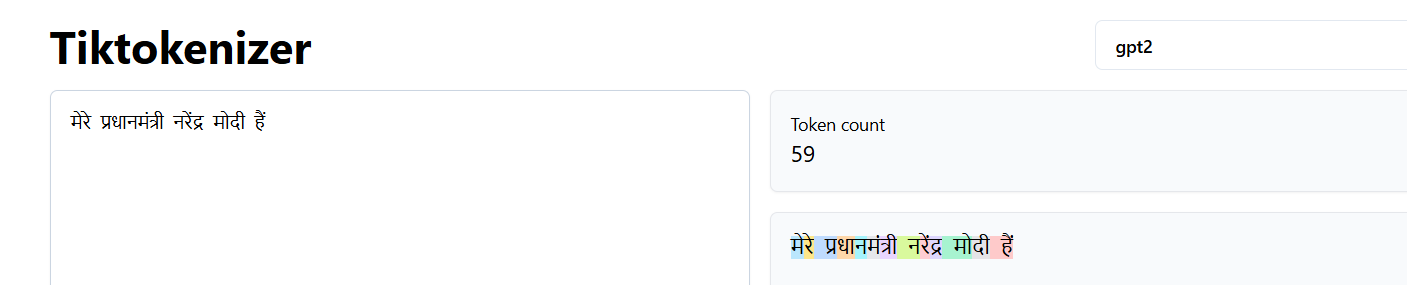
GPT2 tokenization of Hindi - 59 tokens
Tokenization of python code
Similarly models that are trained in programming languages would show lesser tokens than the ones that are not trained in them, when the text presented is a programming language.
Considering the following programing snippet, and comparing the tokenizations across the different models -
def categorize_number(number):
if number > 0:
print("The number is positive.")
if number % 2 == 0:
print("It is also even.")
if number > 100:
print("And it is greater than 100.")
else:
print("But it is 100 or less.")
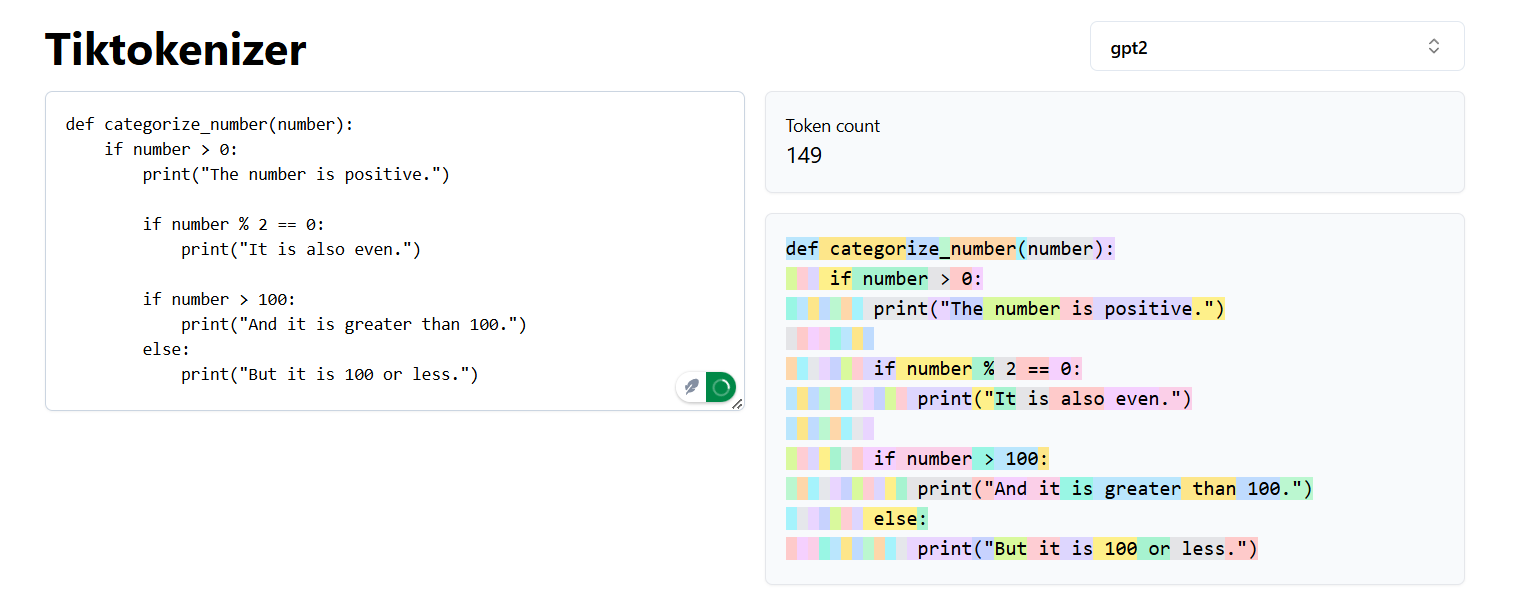
GPT2 tokenization of the above code - 149 tokens
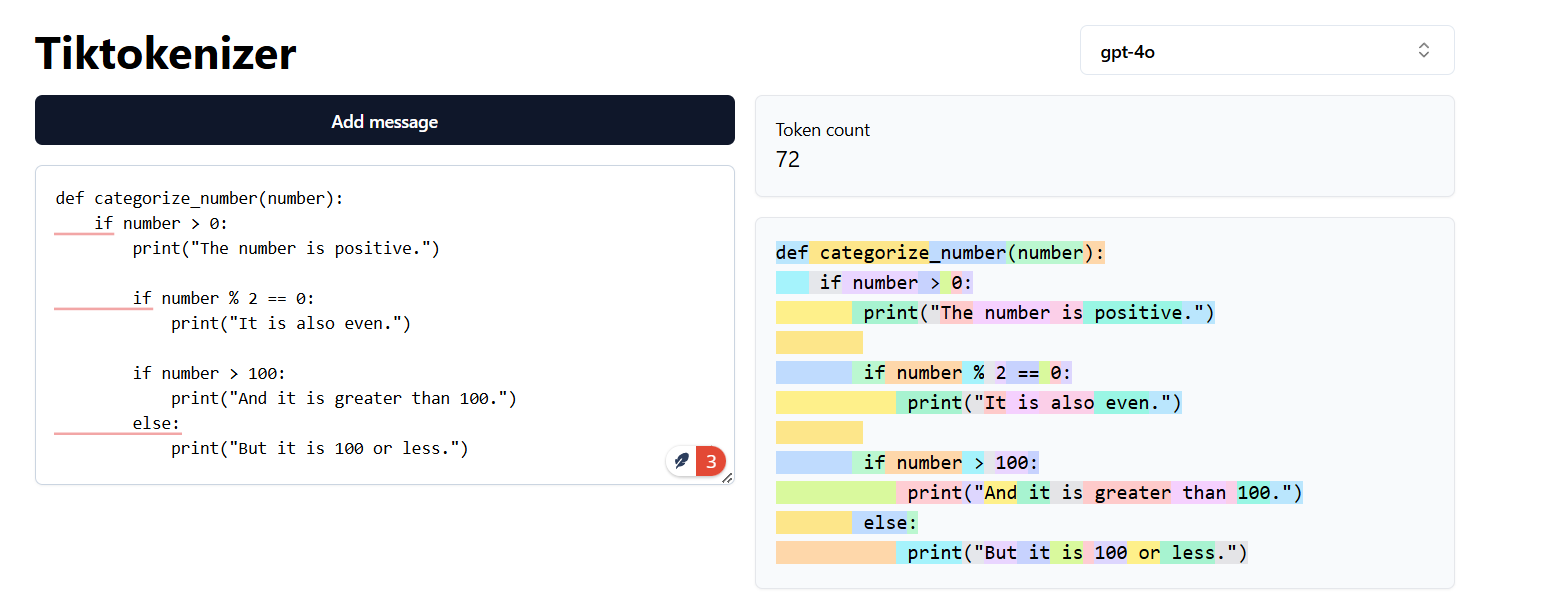
GPT4o tokenization of the above code - 72 tokens
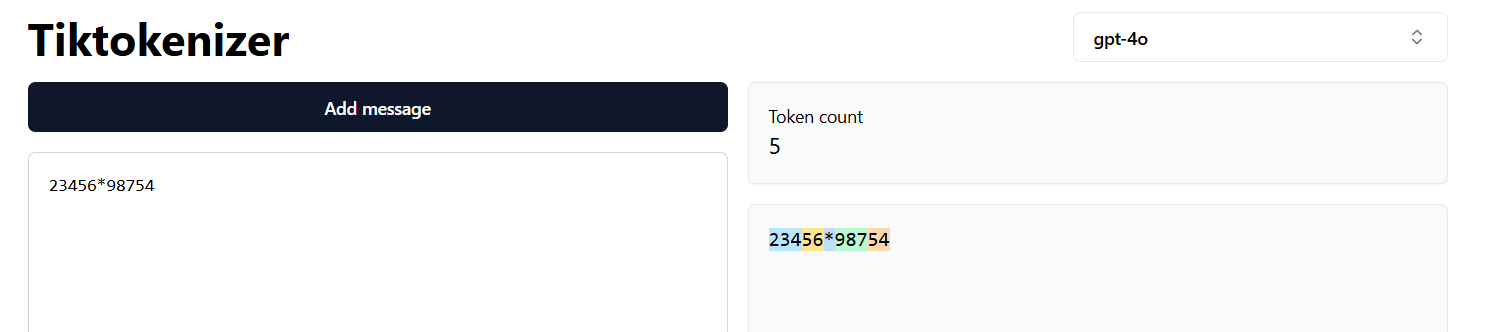
Maths tokenization
- There should be a separate block in LLMs for mathematical problems. Even graph related problems. This is because the textual tokenization does not fit in for mathematical problems.
- We can go the agentic way to do functional calls to do mathematical operations using LLMs. But that is parting ways from text based tokenization or utilization of Transformer architecture in actually deriving the mathematical solutions.
Note below how numbers are broken randomly in between as if they are texts.
Word based tokenization
Code base for building a word based tokenizer
import re
text = "Hello, world. This, is a test."
result = re.split(r'(\s)', text)
print(result)
Output : ['Hello,', ' ', 'world.', ' ', 'This,', ' ', 'is', ' ', 'a', ' ', 'test.']
result = re.split(r'([,.]|\s)', text)
print(result)
Output : ['Hello', ',', '', ' ', 'world', '.', '', ' ', 'This', ',', '', ' ', 'is', ' ', 'a', ' ', 'test', '.', '']
# item.strip() removes any leading and trailing whitespace from a string.
# The condition if item.strip() ensures that only non-empty strings remain in the list.
result = [item for item in result if item.strip()]
print(result)
Output : ['Hello,', 'world.', 'This,', 'is', 'a', 'test.']
text = "Hello, world. Is this-- a test?"
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]
print(result)
Output : ['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']
# Strip whitespace from each item and then filter out any empty strings.
result = [item for item in result if item.strip()]
print(result)
Output : ['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']
Loading the entire corpus
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character:", len(raw_text))
print(raw_text[:99])
Output :
Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(preprocessed[:30])
print(len(preprocessed))
Output :
['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in']
4690
all_words = sorted(set(preprocessed))
vocab_size = len(all_words)
print(vocab_size)
Output : 1130
vocab = {token:integer for integer,token in enumerate(all_words)}
for i, item in enumerate(vocab.items()):
print(item)
if i >= 50:
break
Modularizing the code
Step 1: Store the vocabulary as a class attribute for access in the encode and decode methods
Step 2: Create an inverse vocabulary that maps token IDs back to the original text tokens
Step 3: Process input text into token IDs
Step 4: Convert token IDs back into text
Step 5: Replace spaces before the specified punctuation
class SimpleTokenizerV1:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [
item.strip() for item in preprocessed if item.strip()
]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
#Converts a list of integers (ids) into corresponding strings using the int_to_str dictionary (presumably mapping integers to strings).
# These strings are then joined together with a space between them to form a single string.
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
# Replace spaces before the specified punctuations
text = re.sub(r'\s+([,.?!"()\'])', r'\1', text)
return text
using the tokenizer class
tokenizer = SimpleTokenizerV1(vocab)
text = """"In the dimmest corner of her boudoir"""
ids = tokenizer.encode(text)
print(ids)
Output : [1, 55, 988, 339, 290, 722, 539, 225]
tokenizer.decode(ids)
Output :
" In the dimmest corner of her boudoir"
Adding special context tokens
| vocabulary and tokenizer implemented in the previous section, SimpleTokenizerV2, to support two new tokens, “< | unk | >” and “< | endoftext | >” |
| ”< | unk | >” : token if a word is encountered that is not part of the vocabulary. |
| ”< | endoftext | >” : token to indicate the end of a text sequence - a book or a document. |
class SimpleTokenizerV2:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = { i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
preprocessed = [
item if item in self.str_to_int
else "<|unk|>" for item in preprocessed
]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
# Replace spaces before the specified punctuations
text = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)
return text
tokenizer = SimpleTokenizerV2(vocab)
text1 = "Hello, do you like tea?"
text2 = "In the sunlit terraces of the palace."
text = " <|endoftext|> ".join((text1, text2))
print(text)
Output :
Hello, do you like tea? <|endoftext|> In the sunlit terraces of the palace
tokenizer.encode(text)
Output:
[1131, 5, 355, 1126, 628, 975, 10, 1130, 55, 988, 956, 984, 722, 988, 1131, 7]
tokenizer.decode(tokenizer.encode(text))
Output :
<|unk|>, do you like tea? <|endoftext|> In the sunlit terraces of the <|unk|>.