Machine learning models
- Discriminative models - traditional machine models.
P(Y|X) - given X, predict Y.Labelled data is needed- Train the model with all independent variables and dependent variables.
- for example if I want to train a model to predict correctly whether an MRI scan is cancerous or not,
- First - pass all the X variables (features) of the MRI scan to the model, pass all Y.
- The model understands the pattern of the data on which it is trained. Basically it forms an equation between X and Y, giving $y=f(x)$
- since now, the model has the $f(x)$ , I can pass any unknown x for which the model was never trained, and it will give me $y$
- The model is constricted to predict only type of prediction.
- Generative models - generative models learn the joint distribution
P(X,Y) - fine the probability when X and Y happen together. They generate new data based on the inputs. Labelling is not needed.- Where the mind is without — : the next token is predicted based on the past inputs. So, these supervised models are known as autoregressive models.
- Examples: GPT, BERT, T5, LLaMA, PaLM,
- A generative model is first trained with lots of data. that is known as corpus. I am not labelling the output.
- Transformers like GPT, BERT etc are first trained with all the data in the internet. But none of these data are labelled. Not lablled means training data just passes X. It does not care about Y.
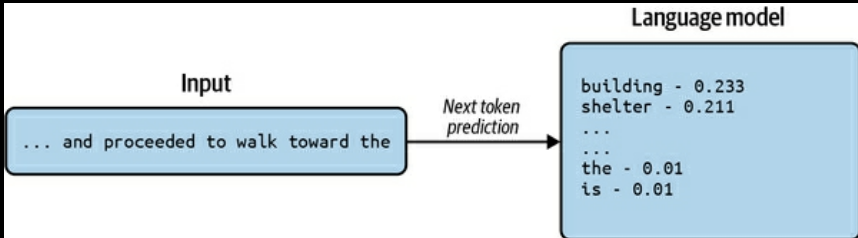
- When transformer architecture works, it takes the past data (X) and predicts the next token (Y).
- basically Ys are determined by shifting the window one token to the right each time the model tries to predict the next token.
- There is no explicit labelling or supplying of ys. Ys are automatically derived from Xs. i.e. the last X is the Y, before predicting the new token. So, such models are known as Auto-regressive models. These are also known as Generative Models
- They can predict text, music, images, videos, 3D objects, etc. The same model knows how to predict anything. This universal nature of the model is what makes it so powerful.
- Corpus - Set of all the training data with which an LLM is trained. Typically this would all the books published, entire internet, contents of all libraries, etc.
- Vocabulary - Set of all the tokens that the model knows. For example, if the model is trained with English language, it will have a vocabulary of all the words in English. Typically say if a vocabulary has 10,000 tokens. LLM will predict probability of all these 10m,000 tokens each time for the next token. Then it will select the token with highest probability as the next token.
- Emergence property - when LLMs are trained using huge data sets, they start predicting things that they were not trained for in the first instance. For example, if the model is trained with English language, it will start predicting French, Spanish, etc. This is known as emergence property of LLMs. It can start predicting airline schedules, chess moves, DNA sequence, or trajectory based operations in flight deck.
- Generative models beyond texts - As the generative models can predict the next token by identifying the probability of all the tokens in its vocabulary, it can also be used to predict any physical phenomenon that can be encoded into discrete sequence using a finite vocabulary. However, the discrete nature of natural language and the inherent structure of the language itself is found to be critical in the success of the model training. The training of videos and audios has not been found that effective.
- discrete nature of text and structure of a language makes this more effective for this model to work. #todo why has the image and vide research not effective as text? william wang x