Stages of building an LLM

Stage 1.1 Data preparation and sampling
Key steps
Batch generation of input-output pairs
1. Auto-regressive nature of LLMs.
The LLM is trained to predict the next token id, given the previous token ids. This is done by feeding the model a sequence of token ids and training it to predict the next token id in the sequence. The model learns to generate text by predicting one token at a time, using the previously generated tokens as context. The auto-regressive nature of LLM means that the model generates text in a sequential manner, one token at a time, based on the context provided by the previously generated tokens.
The training set is the previous generated token.
2. Vocabulary creation from corpus

The first step is to create token ids. This is typically produced using Byte Pair Encoding algorithm.
- Note that the |<endoftext>| is used to mark the word separation. the word separation token is always honored in sub-work tokenization.
- The token ids are generated on the entire corpus. This is the process where the following was done internally as per BPE -
- Convert the corpus into characters.
- Create ids for each of the characters.
- Merge the character pairs which occur most common in the corpus.
- Assign a new id (max id +1) to the new character pair created.
- Create a list of ids after doing all the merges based on the corpus
- Note that we are handing corpus only as of now as input, and we are generating the token ids based on the corpus.
- This list of token ids which their sequence preserved as that was in the corpus is the vocabulary.
3. Context size or Context window
The maximum number of token ids that the LLM can considers at once, to predict the next token id is known as context size or context window.
4. Input-target pair preparation
Let us say that the context size is n. That is the max number of token ids that can be sent to the Transformer.
To process the entire context window of size n, there will be n input-target pairs formed.
Say the context size is 9. The 9 input-target pairs will be as follows. 9 tasks will be created, predicting one token at a time. The training set for each subsequent tasks will keep increasing by one token. In the figure below, blue tokens are training sets, and red tokens are the predicted token for the corresponding tasks. The tasks happens one row at a time.
5. Details steps and code
Step 1 : Create the token ids or vocabulary from corpus
import importlib
import tiktoken
tokenizer = tiktoken.getencoding("gpt2")
with open("the-verdict.txt", "r", encoding="utf-8") as f:
corpus = f.read()
# creating the token ids or vocabulary maintaining the sequence in the corpus.
enc_text = tokenizer.encode(corpus)
# taking a sample of the token ids to demonstrate the concept
enc_sample = enc_text[:32]
for token, decoded in zip(enc_sample, tokenizer.decode_batch([[t] for t in enc_sample])):
print(f" {decoded}:{token} ,", end = "")
Output >>
I:40 , H:367 , AD:2885 , always:1464 , thought:1807 , Jack:3619 , G:402 , is:271 , burn:10899 , rather:2138 , a:257 , cheap:7026 , genius:15632 , --:438 , though:2016 , a:257 , good:922 , fellow:5891 , enough:1576 , --:438 , so:568 , it:340 , was:373 , no:645 , great:1049 , surprise:5975 , to:284 , me:502 , to:284 , hear:3285 , that:326 , ,:11 ,
Step 2 : Data sampling with sliding window
Using the token ids that are created above, or encoded above, now the LLM would be trained, using auto-regression. Here the training set and test set will be taken one token at a time, using two sliding windows.
- training sliding window
- test sliding window
The size of each of the above windows will be same as the context window size.
# context size is constant for a LLM. These many tokens are sent at one time as test and training set.
import numpy as np
from pprint import pprint
context_size = 4
matrix_row = int(len(enc_sample)/context_size)
print (f"matrix row = {matrix_row}")
matrix_col = context_size
pointer = 0
x_list = []
x_text_list = []
y_list = []
y_text_list=[]
for i in range(matrix_row):
start_index = pointer
end_index = pointer + context_size
x = enc_sample[start_index:end_index]
x_text = tokenizer.decode(x)
y = enc_sample[start_index+1:end_index+1]
y_text = tokenizer.decode(y)
x_list.append(x)
x_text_list.append(x_text)
y_list.append(y)
y_text_list.append(y_text)
print(f"x: {x}", end="")
print(f" x-text: {x_text}")
print(f"y: {y}", end="")
print(f" y-text: {y_text}")
pointer = pointer + context_size
print(f"last token# - {pointer}, matrix row# - {i+1} \n")
print("\n Input token matrix is : \n")
pprint (x_list)
print("\n Input text matrix is : \n")
pprint(x_text_list)
print("\n")
print("\n Output token matrix is : \n")
pprint (y_list)
print("\n Output text matrix is : \n")
pprint(y_text_list)
Output >>
matrix row = 8
x: [40, 367, 2885, 1464] x-text: I HAD always
y: [367, 2885, 1464, 1807] y-text: HAD always thought
last token# - 4, matrix row# - 1
x: [1807, 3619, 402, 271] x-text: thought Jack Gis
y: [3619, 402, 271, 10899] y-text: Jack Gisburn
last token# - 8, matrix row# - 2
x: [10899, 2138, 257, 7026] x-text: burn rather a cheap
y: [2138, 257, 7026, 15632] y-text: rather a cheap genius
last token# - 12, matrix row# - 3
x: [15632, 438, 2016, 257] x-text: genius--though a
y: [438, 2016, 257, 922] y-text: --though a good
last token# - 16, matrix row# - 4
x: [922, 5891, 1576, 438] x-text: good fellow enough--
y: [5891, 1576, 438, 568] y-text: fellow enough--so
last token# - 20, matrix row# - 5
x: [568, 340, 373, 645] x-text: so it was no
y: [340, 373, 645, 1049] y-text: it was no great
last token# - 24, matrix row# - 6
x: [1049, 5975, 284, 502] x-text: great surprise to me
y: [5975, 284, 502, 284] y-text: surprise to me to
last token# - 28, matrix row# - 7
x: [284, 3285, 326, 11] x-text: to hear that,
y: [3285, 326, 11] y-text: hear that,
last token# - 32, matrix row# - 8
Input token matrix is :
[[40, 367, 2885, 1464],
[1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[922, 5891, 1576, 438],
[568, 340, 373, 645],
[1049, 5975, 284, 502],
[284, 3285, 326, 11]]
Input text matrix is :
['I HAD always',
' thought Jack Gis',
'burn rather a cheap',
' genius--though a',
' good fellow enough--',
'so it was no',
' great surprise to me',
' to hear that,']
Output token matrix is :
[[367, 2885, 1464, 1807],
[3619, 402, 271, 10899],
[2138, 257, 7026, 15632],
[438, 2016, 257, 922],
[5891, 1576, 438, 568],
[340, 373, 645, 1049],
[5975, 284, 502, 284],
[3285, 326, 11]]
Output text matrix is :
[' HAD always thought',
' Jack Gisburn',
' rather a cheap genius',
'--though a good',
' fellow enough--so',
' it was no great',
' surprise to me to',
' hear that,']
Number of tasks per context size chunk of tokens in x

In the above code, for the 1st row the tasks will be as follows -
for i in range(1, context_size+1):
context = enc_sample[:i]
desired = enc_sample[i]
print(f"{context} ----> {desired} : ",end="")
print(f"{tokenizer.decode(context)} ----> {tokenizer.decode([desired])}")
Output >>
[40] ----> 367 : I ----> H
[40, 367] ----> 2885 : I H ----> AD
[40, 367, 2885] ----> 1464 : I HAD ----> always
[40, 367, 2885, 1464] ----> 1807 : I HAD always ----> thought
Implementing the end to end data loader as discussed above in pytorch
Dataloader - loading the data to LLM in batches.
- target is always = input + 1
input_chunk = token_ids[i:i + max_length] target_chunk = token_ids[i + 1: i + max_length + 1] - stride is the number or tokens to skip and start the next input.
- context window or max size = number of tokens to be taken in one input pair/output pair.
- batch size - number of input-out pairs loaded to LLM at a time and processed.
Configuring the dataloader
from torch.utils.data import Dataset, DataLoader
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
# Tokenize the entire text
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
# Use a sliding window to chunk the book into overlapping sequences of max_length
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
#Dataset is about defining what your data looks like and how to access it.
#DataLoader is about wrapping that data in an iterator that can handle batching,
#shuffling, parallel loading, and other “housekeeping” tasks needed for training or inference in PyTorch.
def create_dataloader_v1(txt, batch_size=4, max_length=256,
stride=128, shuffle=True, drop_last=True,
num_workers=0):
# Initialize the tokenizer
tokenizer = tiktoken.get_encoding("gpt2")
# Create dataset
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
# Create dataloader
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers
)
return dataloader
Calling the dataloader
- number of column for each of the input and output matrices = context size = 4 = max_length
- number of rows for each of the input and output matrices = batch size = 8
- number of tokens to be skipped before starting the next input pair is = stride = 4
dataloader = create_dataloader_v1(raw_text, batch_size=8, max_length=4, stride=4, shuffle=False)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Inputs:\n", inputs)
print("\nTargets:\n", targets)
# 32 is the input-output times (8 * 4)
Output >>
Inputs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Targets:
tensor([[ 367, 2885, 1464, 1807],
[ 3619, 402, 271, 10899],
[ 2138, 257, 7026, 15632],
[ 438, 2016, 257, 922],
[ 5891, 1576, 438, 568],
[ 340, 373, 645, 1049],
[ 5975, 284, 502, 284],
[ 3285, 326, 11, 287]])
Embeddings generation of the input output pair matrices.
Capturing semantic relationship between words in word2vec
- Just converting tokens texts into number is not enough. These numbers should not be random numbers, but utilize the underlying semantics of the words.
- Using one hot encoding - based on the vocabulary size have a vector of all zeroes. And mark as 1 the position for a given word in the vocabulary.
This does not capture the semantic relationships betweenw ords. dogs and puppy are the two words which are related but puppy appears much much later than dogs. - So, with just numbers we cannot represent the similarities. We need vectors to do so. We can have semantically similar words has same vectors. Vectorization helps to represent the tokens along a space with different dimensions. Each dimension represents one feature.
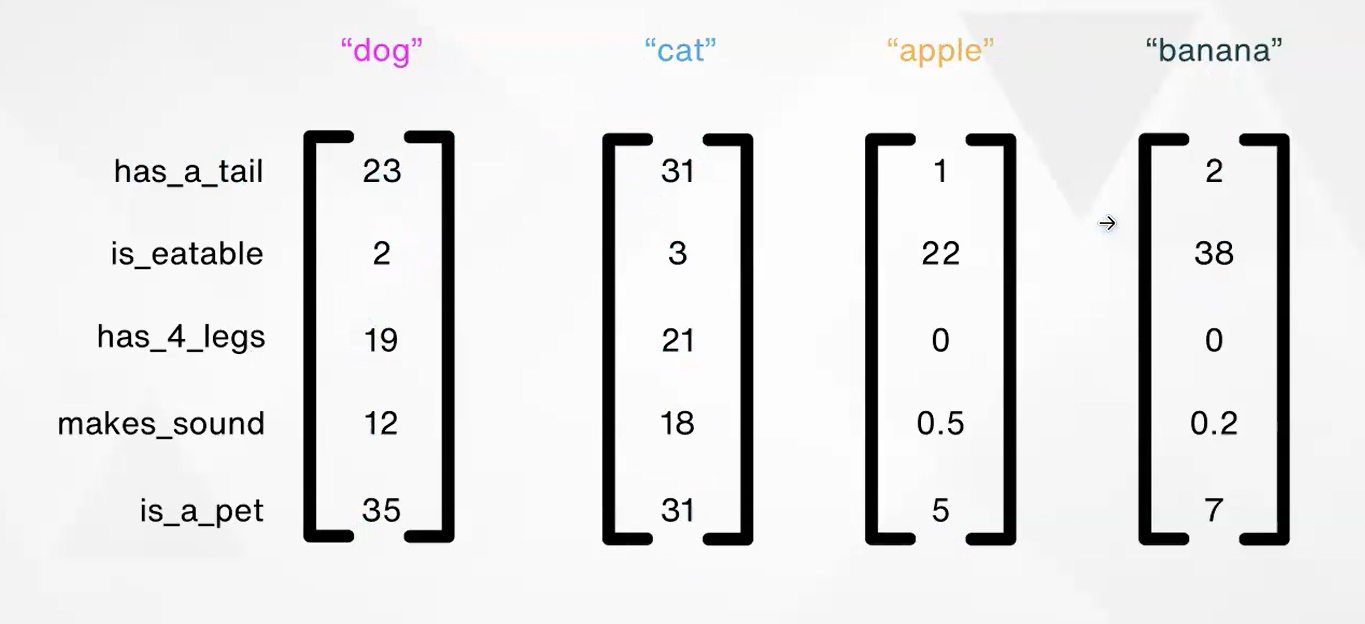
- The dimensions that are there, typically does not have any specific meaning per so. Because if we try to arrange the numbers based on the actual features of theirs, then we are not doing deep learning based learning by the neural network. Rather it would be algorithmic. This illustration above is just a representation of a possible arrangement to give some intuition. The vectors are localized purely on the basis of their proximity in the entire corpus that is used to build the vocabulary in this tokenization / token id creation / embedding phase of data preparation.
- The method in which this feature matrix is created is described in the word2vec paper. The idea was as follows -
- take any word from the corpus
- find a window around that word
- the words within the window - mark them as positive words.
- the words outside the window - mark them as negative words.
- for the positive words make the loss function as low.
- for the negative words make the loss function as high.
- train a neural network with all the words.


- The assumption that neighboring words will have similar semantics might not work with low data set. But when one has a huge amount of data and several documents making a huge corpus, statistically it is found that collocated words are semantically similar.
- So, each token id in the vocabulary is transformed into a multi dimentional matrix which is called as embedding - In this case an embed size of 750. Each dimension is not known. To know their essense is all about Explainability of the neural network

- The 750 - embed size is a configuration parameter that is set before training the mode. Every token is expanded to this new dimension. It is random to start with. Then dot product (cost function) is set for the words that are within the envelop as low and for others as high. This is known as contrastive technique
- In this scheme the antonym of the words will be placed as neighbors. They are opposite. But they are related as being opposite. So “man” and “woman” would appear together. i.e their embed vectors are similar. Same will be the case with “king” and “queen”
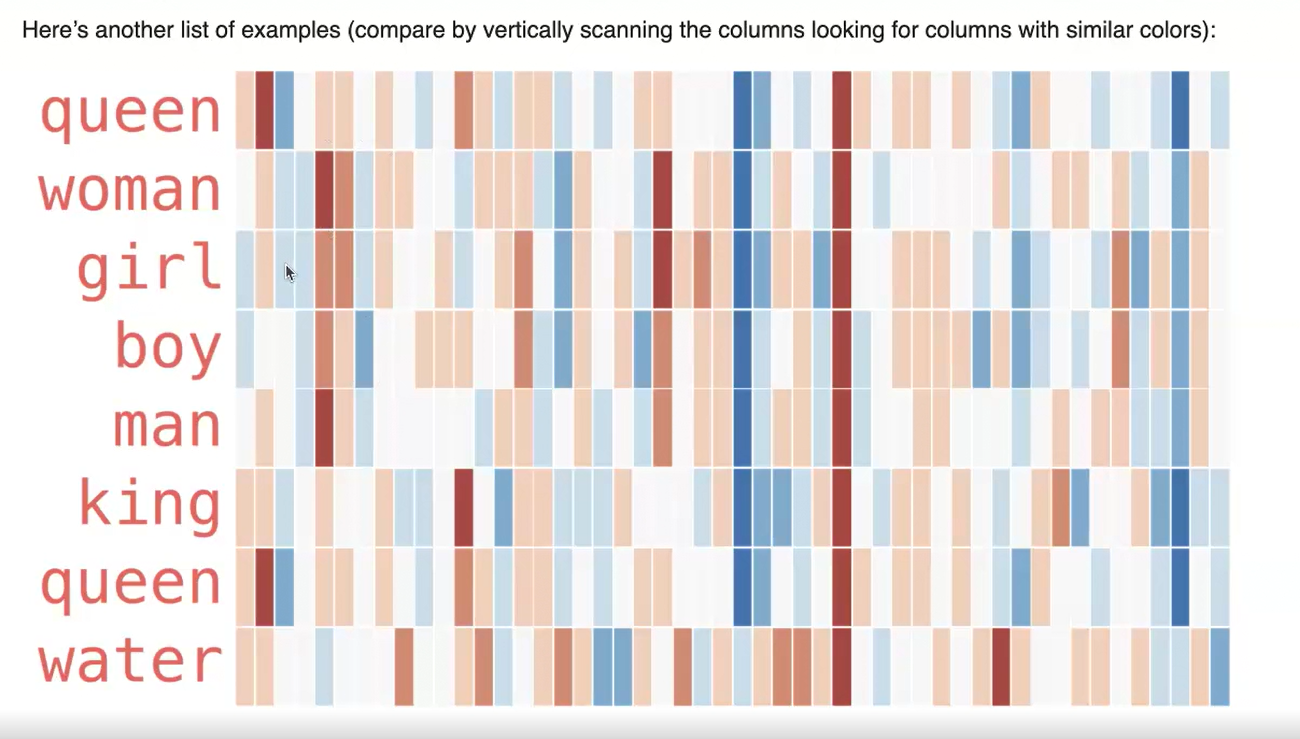
- The concept of neighbors and non-neighbors exists only in the case of word2vec. That is not used in the LLM training. In the case of LLM, directly each token id is taken and it is converted to an embedding based on the neural network output. Neighbors and non neighbors concept is totally missing in LLMs.
- Code implementing the word2vec
code base for the word2vec implementation
Capturing semantic relationships in LLMs
-
The token embeddings are different from the word2vec embeddings. Here neighbor and non-neighbor concept is not used. The token ids are directly converted to embeddings using a neural network. These embeddings are not static, but are trained during the pre-training phase of the LLM.

-
The journey from input text, to character tokens to token ids, to input - output pairs, to batch size, to token embeddings illustrated below -

-
Code details - When we call nn.Embeddings() it basically does a lookup of the embedding matrix and retrieves the vector embeddings for the needed token ids. The code goes something like this -
input_ids = torch.tensor([2, 3, 5, 1])
vocab_size = 6
output_dim = 3
torch.manual_seed(123)
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
print(embedding_layer.weight)
Output >>
Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)
#--------------------------------------------------------------
# direct lookup from token id to vector embedding
print(embedding_layer(torch.tensor([3])))
Output >>
tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=<EmbeddingBackward0>)
#--------------------------------------------------------------
print(embedding_layer(input_ids))
tensor([[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-2.8400, -0.7849, -1.4096],
[ 0.9178, 1.5810, 1.3010]], grad_fn=<EmbeddingBackward0>)
- Batch size is the number of input-output pairs that are sent to the LLM at a time. The batch size is a configuration parameter that is set before training the model. The batch size is typically set to a power of 2, such as 32, 64, or 128, to take advantage of the parallel processing capabilities of modern GPUs. The batch size can also be adjusted based on the available memory and computational resources.
- Gradient update is done for the entire batch size. The loss function is calculated for each input-output pair in the batch, and the gradients are averaged over the batch size before updating the model parameters. This allows the model to learn from multiple examples at once, improving the efficiency of the training process, one batch at a time.
- At one time, only one part of the input and output matrix is processed and the gradient is updated
- Each row is processed by different tasks of prediction of one token at a time, given the input as a string of previous tokens. Number of tokens is equal to the context size.
-
One input - output pair, requires number of steps = context size. In this case if context size is 4, there will be 4 prediction task for each input-output pair prediction.
- Full Code base for llm embedding