
Key concepts
- RAG pairs an LLM with a knowledge base
- Data is private, recent, or highly specific and so missing from the LLM’s training data
- Retriever finds relevant documents based on the query from the knowledge base and adds them to an augmented prompt
- LLMs grounds their response in the retrieved information.
graph TD
A[User Query] --> B[Retriever]
B --> C[Knowledge Base]
C --> D[Relevant Documents]
D --> E[Augmented Prompt]
E --> F[LLM]
F --> G[Response]
Retrievers
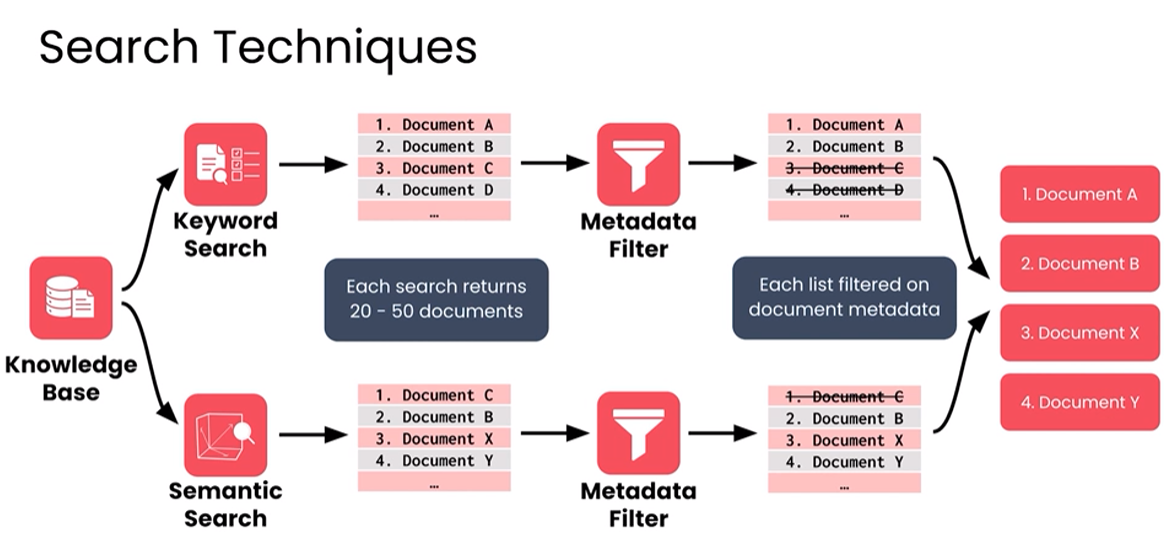
Two types of searches (Hybrid Search)
- Keyword search - looks in the documents containing exact words found in the prompts.
- Semantic search - looks for the documents with similar meaning to the prompt.
- Metadata filtering - narrow down the search results based on metadata attributes (e.g., date, author, category).
- Sparse vector search (traditional search)
- Dense vector search (modern search)
- Embeddings + vector DB (FAISS, Pinecone, Weaviate, etc.)
- Hybrid search (combination of both)
- Combines the strengths of sparse and dense vector searches for improved retrieval performance.
TF-IDF (Term Frequency-Inverse Document Frequency) search