Retrieval Augmented Generation (RAG) - Intro
Basic RAG architecture
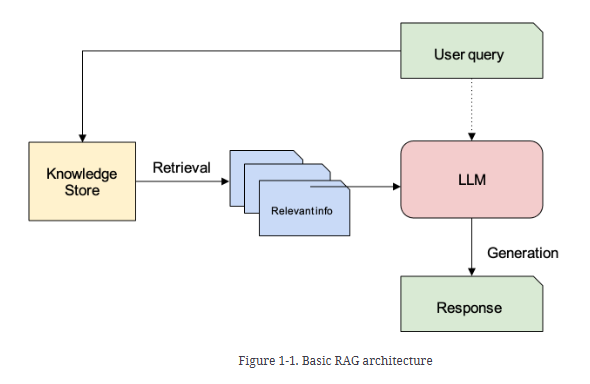
For the query “What are the effective treatments for diabetes?”, the Retrieval step will, at least ideally, bring back information that is related to the treatment of diabetes and leave treatment of other conditions or causes of the condition out. Then, the Generation step will separate, in the hidden state of an LLM, effective and ineffective treatments that have been tried and only present effective ones to you.
The word “augmented” in “Retrieval Augmented Generation” suggests that the retrieved information is added (that’s the meaning of the word “augment”) to the prompt of an LLM for generation. A RAG prompt typically looks something like this:
Here is a user query: {query}.
And relevant context:
{context}
Please respond to the user query using the context
RAG stack
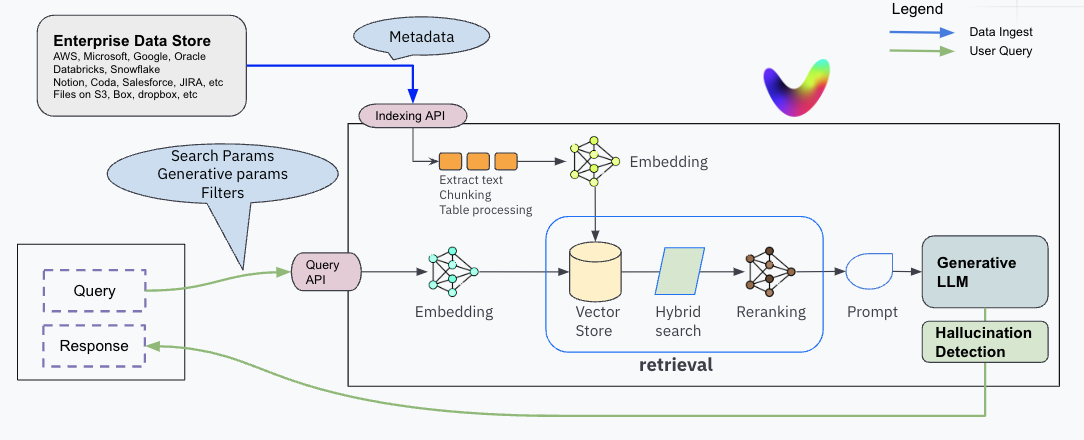
There are two flows -
:bulb: 1. data ingest flow: The ingest flow performs those functions needed to extract the data from its source (like a database, a set of PDF files on S3, text on Notion, etc) and index it into the RAG stack.
:bulb: 1. user query flow: The query flow performs the full processing of a user query - retrieves the right facts and uses the LLM for generative summary, resulting in a response to the end user.
Data Ingest flow
During data ingestion, the RAG system first converts the input data (against which user queries will be answered) into vectors, also known as embeddings (or vector embeddings). These vectors represent the semantic meaning of the text, and as we will see Chapter 2 are a very powerful mechanism to match a query to a fact. The vector embeddings are then stored in a special database called a vector database or vector DB. Alongside each vector, the actual text is also stored as it is needed for query time processing. The step of converting data into vectors is often referred to as indexing or embedding.
Note that in the RAG world, the word index, dataset or corpus are somewhat synonymous - they all ultimately mean the storage mechanism where the text data is stored. With more advanced RAG, the index may also contain tables, charts, images or videos.
User Query flow
- user query embedding - The query flow starts with converting the user query into an embedding, and then the vector DB performs a similarity match operation between the query embedding and all possible matching text (the facts) in the vector DB.
- Retrieval based on similarity search in the vector db -
Chunking strategies
- Fixed size chunking - never use for structured documents. use it for high speed of processing in streaming of sensor data. unstructured data like reddit, twitter etc. millions of web pages scapping.
- Semantic chunking -
- define a level of organization - sentence, paragraph, section, chapter etc. it is better to have para level as semantically similar ones are together.
- find the cosine similarity of the entire document for that do structure and keep the similar units in one chunk
- when you get a new chunk that is dissimilar, create a separate chunk.
- Recursive chunking
- best of both worlds.
- exploits the structure of documents and chunk size are consistent.
- first make the chunking based on structure
- make max chunk size as say 500.
- keep recursively chunking - section -> paragraph -> sentence
- Structural chunking (structural chunking is done first. then fixed size is applied when one section is larger than max chunk size)
- Chunks
- chunk a - letter to share holders.
- chunk b - introduction
- chunk c - compoany overview
- chunk d - financial stattements
- chunk e - notes to financial statements
- chunk f - conclusion and outlook
- Issues -
- how about when one section is huge? it will not fit to context window of LLM
- meta data - you can know which chunk belongs to which section.
- Chunks
- LLM chunking
- Context drift in the conversations - fully unstructured data.
Vector db
References
- RAG Paper
- Gemini large context window
- Pymupdf - only for digital characters
- OCR library - Tesseract - handwritten or scanned
- tabular data and ocr - docling
- docling technical report
- Mistral OCR
- [Internet scraping - Firecrawl]
- [HTLM only - beautifulsoup]
- [js based pyppeteer - automate scraping only paragraph, heading, etc. workflow definition for multiple sites]
- colqwen2
- [Hands On RAG, Oreilly, Ofer Mendelevitch, Forrest Bao]