Saturday 8-09-2025 - runtime tool calling, agentic workflow in loop
Presenter - Samrat Kar
Notes and references for the session
i have updated the single agent, multiple tools code to have the following fixes -
- implemented a multi-pass ReAct agent, where out of the LLM is again passed back to the LLM to think, evaluate and call appropriate tools
- added the following 8 tools to the agentic workflow - rag call for usa economics related queries, add, multiply, divide, get latest stock data, connect to mcp weather server, search internet, call llm for general knowledge on which it was trained
- removed the router to avoid any hardcoding of the routing of the control to appropriate function tools. instead the routing is done entirely by the llm based on the prompts and the doc string provided in the respective function tools.
- solved the problem of infinite looping when control was being sent back to llm.
- integrated the mcp client as a separate tool in the same workflow, instead of a separate app. mcp server needs to be run in the background for this mcp client tool to be called. if mcp server is not running, direct internet search will be done automatically and results will be provided.
- in the jupyter was not able to call the asynch mcp server agent call. so have made the code as simple python code, instead of jupyter notebook.
- configured the search tool to output only in English.
- fine tuned the prompts and doc strings in the tools to get the right results
Here is the latest code - https://github.com/samratkar/samratkar.github.io/blob/main/_posts/concepts/agentic_ai_2_0/3-Langraph/tools_agent_no_router_loop_mcp.py
i have provided sample test queries to go through all the workflow paths. just uncomment the appropriate query and run the code.
Steps of execution -
- Run the mcp server : Got to the folder where the weather.py resides and run the command -
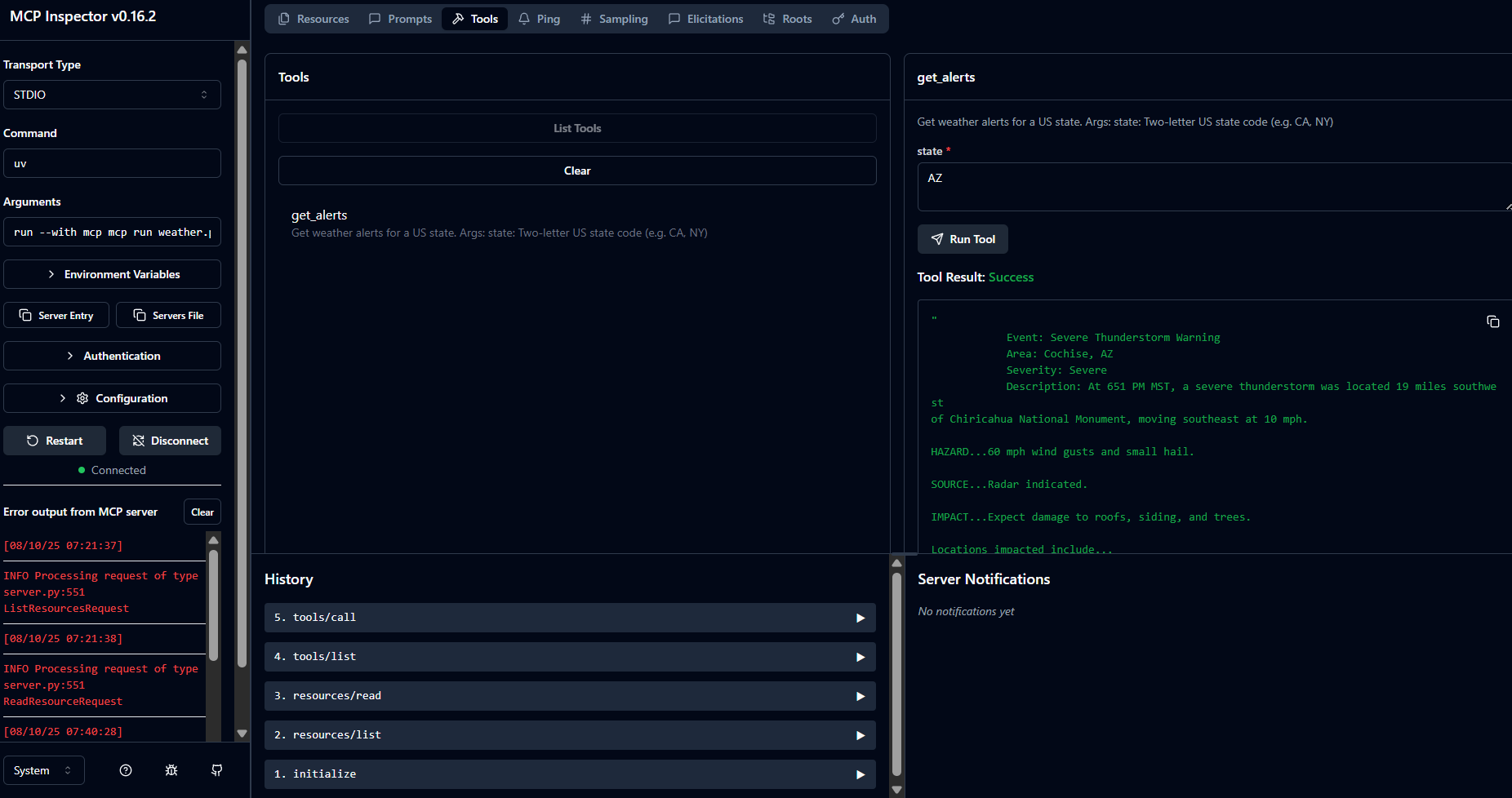
uv run mcp dev weather.py - Ensure MCP inspector is able to connect to the weather mcp server and retrieve weather information
- Run the multi agent workflow code : Go to the folder where the tools_agent_no_router_loop_mcp.py resides and run the command -
python tools_agent_no_router_loop_mcp.py
Output -
MCP Server invocation

MCP server working and retrieving weather information
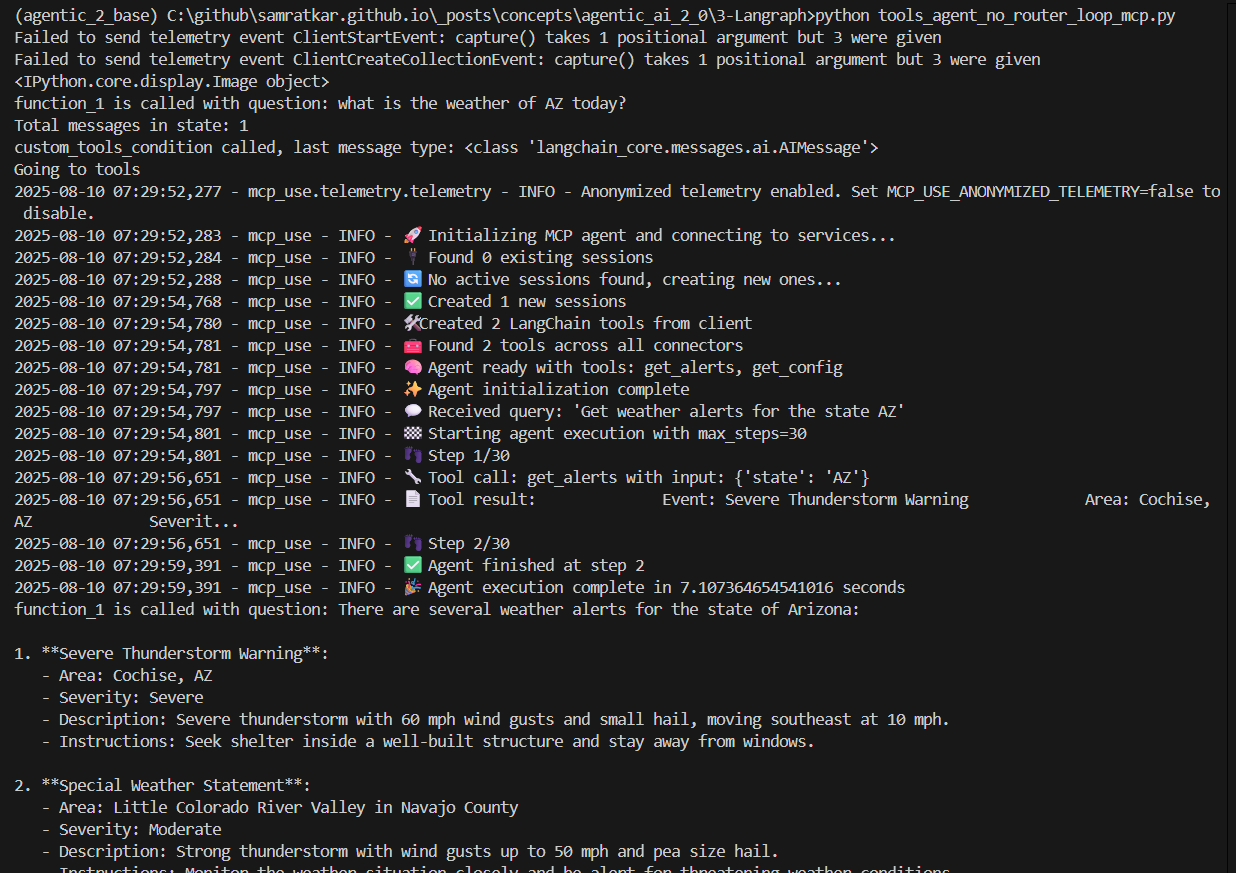
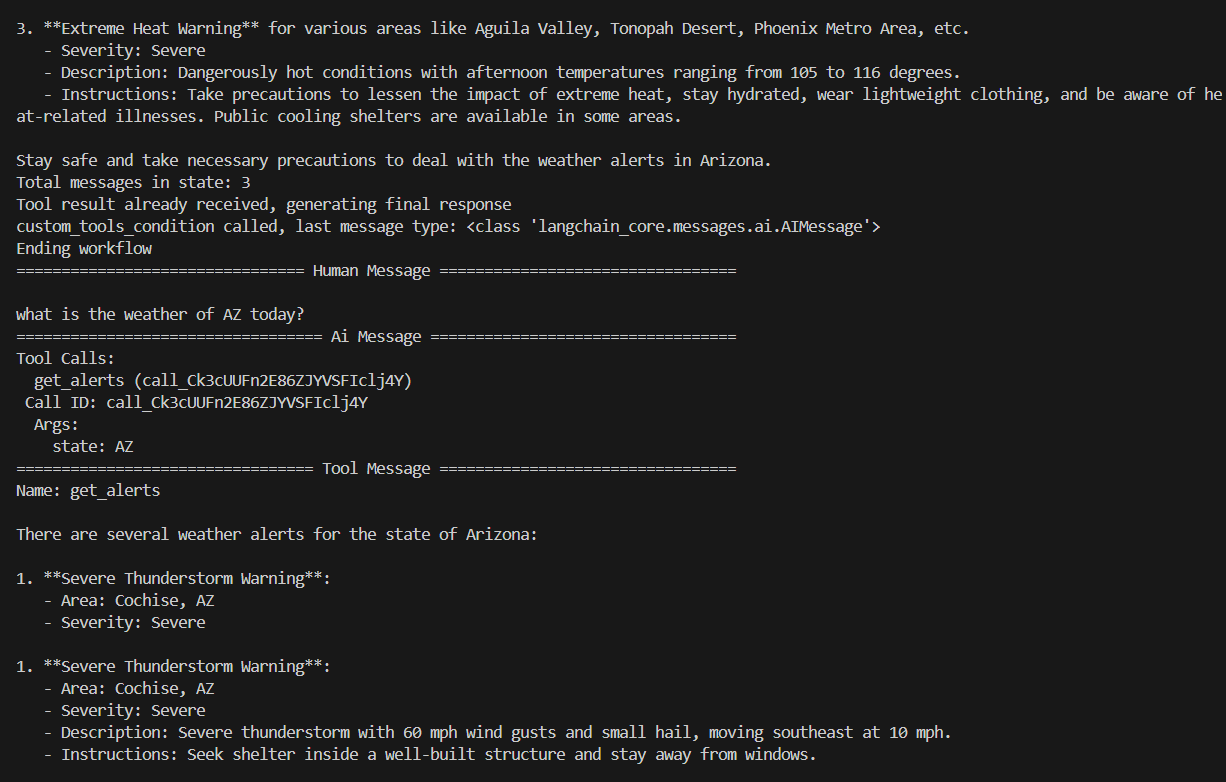
Execution of the agentic workflow app
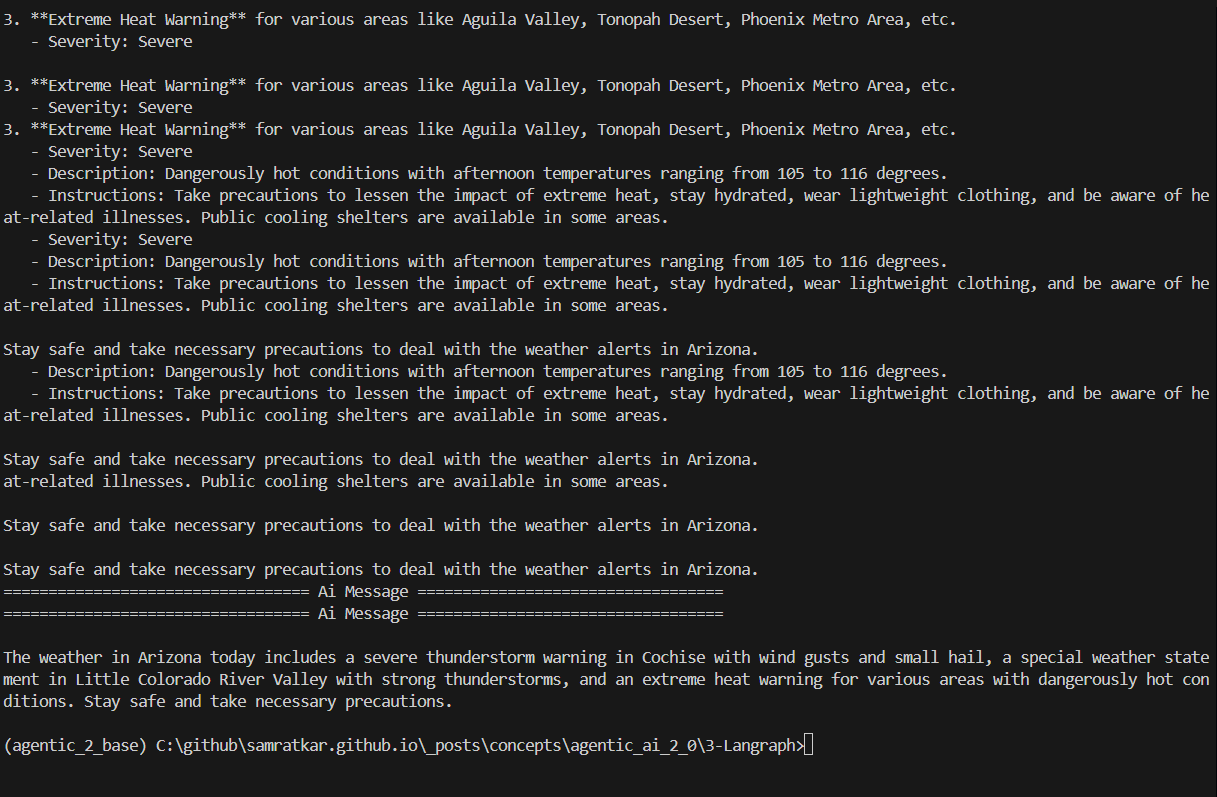
Saturday 8-2-2025 - MCP server, client, integration of MCP server with LLM, agentic workflow
Presenter - Samrat Kar
Notes and references for the session
- design time agentic workflow - manually wiring all the function tools in code - https://github.com/samratkar/samratkar.github.io/blob/main/_posts/concepts/agentic_ai_2_0/3-Langraph/weather_rag_gen_nodes.ipynb
- hybrid agentic workflow - letting LLM design in run time which function tool to call in run time. - but still hard coding entry and exit from function tools in a forward direction using design time workflow - (hybrid mode) - https://github.com/samratkar/samratkar.github.io/blob/main/_posts/concepts/agentic_ai_2_0/3-Langraph/weather_rag_gen_hybrid_tools_mcp.ipynb
- wrapper on an external mcp server (weather api) - https://github.com/samratkar/samratkar.github.io/blob/main/_posts/concepts/genai/notes-codes/mcp/mcp-kn/mcpcourse/server/weather.py
- weather.jso - giving details of the weather mcp server - https://github.com/samratkar/samratkar.github.io/blob/main/_posts/concepts/genai/notes-codes/mcp/mcp-kn/mcpcourse/server/weather.json
- client calling an LLM model to invoke the MCP server and provide the output - https://github.com/samratkar/samratkar.github.io/blob/main/_posts/concepts/genai/notes-codes/mcp/mcp-kn/mcpcourse/server/client.py
Video recording
Passcode - 5.bz^c?K
Sunday 7-20-2025 - Intro to deep learning and Transformer architecture overview
Presenter - Samrat Kar
Notes and references for the session
Video recording
Saturday 7-19-2025 - Building a single agent multi tool system
Presenter - Samrat Kar
Code
Single Agent Multi Tool System - Code
Video
Passcode - *&31fWJH
Sunday 7-13-2025 - Generative AI System Design
Session 1 - Introduction and overview - Chapter 1
Presenter - Barath
Reference Text
Generative AI - System Design Interview - An Insider’s Guide - Ali Aminian & Hao Sheng
Session video recording
Generative AI System Design - Session 1 - Video
Passcode - 69!rTvp4
Topics covered -
- Difference between Generative Model and classical discriminative models. Maths behind GAN
- Discriminative models and supervised ML models that classify or predict data based on labelled training data. Generative model does not need labels done separately.
- Common examples of Discriminative models are -
- Logistic Regression - A linear model that predicts the probability of abinary outcome based on input featuers.
- Support Vector Machines (SVM) - A model that finds the optimal hyperplane to separate data points of different classes. They can be extended to learn non linear boundaries using kernel functions.
- Decision Trees - A model that splits the data into subsets based on feature values, creating a tree structure to make predictions.
- K Nearest Neighbors (KNN) - A model that classifies data points based on the majority class of their k nearest neighbors in the feature space.
- Neural Networks - A model that uses layers of interconnected nodes to learn complex patterns in data. They can be used for both classification and regression tasks.
While these algorithms can predict a target variable from input features, most of them lack the capability to learn the underlying data distribution needed to generate new data instances.
- Generative Models - Generative models aim to understand and replicate the underlying distribution of data. Formally, they model the distribution P(X) when focusing solely on the input data (image generation), or the joint probability distribution P(X,Y) when considering both the input data and the target variable (eg - text to image generation)
- Generative Models can be divided into two categories -
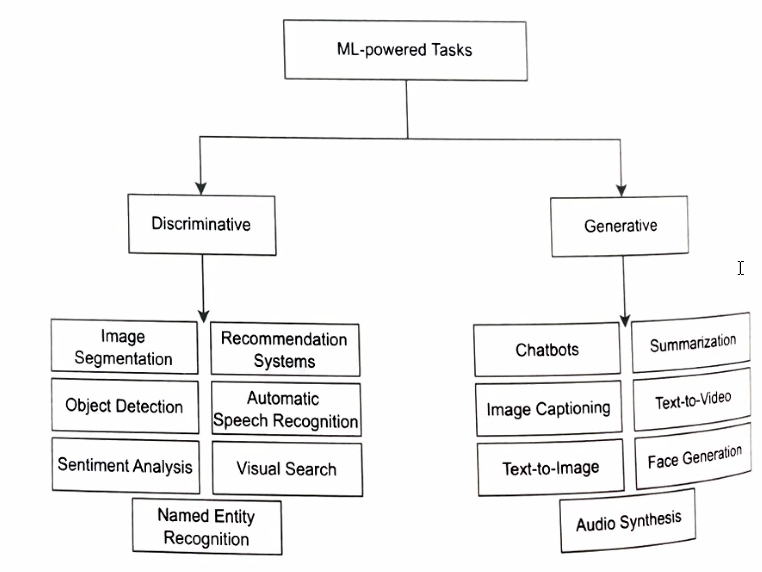
- Common classical generative algorithms
- Naive Bayes - A probabilistic model that applies Bayes’ theorem with the assumption of independence between features. It is often used for text classification tasks.
- Gaussian Mixture Models (GMM) - A probabilistic model that represents a mixture of multiple Gaussian distributions to capture the underlying data distribution. It is commonly used for clustering tasks.
- Hidden Markov Models (HMM) - A statistical model that represents a sequence of observations as a Markov process with hidden states. It is widely used in speech recognition and natural language processing tasks.
- Boltzmann Machines - A type of stochastic neural network that learns the joint probability distribution of a set of variables. It is used for unsupervised learning and generative tasks.
- Modern generative algorithms
- Variational Autoencoders (VAE) - A generative model that learns a latent representation of the input data and can generate new samples by sampling from the learned distribution.
- Generative Adversarial Networks (GAN) - A framework that consists of two neural networks, a generator and a discriminator, that compete against each other to generate realistic data samples.
- Diffusion Models - A class of generative models that learn to reverse a diffusion process to generate new samples from noise.
- Large Language Models (LLM) - These are generative models that can generate human-like text based on the input prompt. They are trained on large corpora of text data and can be used for various natural language processing tasks.
- Common classical generative algorithms
- Why the generative models are so popular?
- The Generative models can perform various tasks across various domains such as generating text, creating realistic images, and composing music. The multi-tasking capability makes them valuable across industries, from creative arts and entertainment to healthcare and software development.
- Generative models significantly enhance productivity by automating content creation, data augmentation, and design processes. They can generate high-quality outputs with minimal human intervention, allowing professionals to focus on higher-level tasks and innovation.
- What drives the advancement of the Generative Models?
- Unlabeled Data for training : Unlike classical models that typically work well when trained on labeled data, Generative models can learn from unlabeled data. They are auto-regressive in nature. This approach lets them use vast datasets from the internet without hte need for costly and time consuming labeling processes. So, just by giving the huge data in the internet, libraries and universities, the models can be trained.
- Llama 3 was trained on 15 Trillion tokens - 50 TB of data.
- Google’s Flamigno model was trained on 1.8 billion (image,text) pairs.
- Model Capacity - Another key factor in effectiveness of ML models is their capacity to learn. Model capacity is measured in two ways :
- Number of parameters / features - Number of features determine the learning capacity of the model
- Google PaLM - 540 B parameters
- Open AI GPT-3 - 175 B parameters
- Google’s Flamingo - 80 B parameters
- Meta’s Llama 3 - 450 B parameters
- Google’s Imagen - 2 B parameters
- Number of parameters / features - Number of features determine the learning capacity of the model
- FLOP count - Floating point operations measure the computational complexity of a model by counting hte floating point operations required to complete a forward pass. Dense layers typically require more FLOPs than sparse connections, even if the parameter count is the same.
- Compute - More the parameters / features on which the models are trained, better is their capacity to learn. But to be able to train the model requires enormous amounts of computational resources. Training advanced GenAI models is expensive, requiring thousands of GPUs over weeks long periods. GPT-4 was trained at a cost of $100 million. Training the models with billions of parameters was not possible just a few years ago. The shift in capability has been mainly due to hardware advancements, particularly the specialized hardwares like GPUs and TPUs. designed for deep learning tasks. Distributed training techniques have also enabled training of larger models across multiple machines, further enhancing the scalability and efficiency of the training process.
- Scaling Law - As the features are scaled, the learning capacity of the models increase, and that in turn leads to several emergent properties that was not thought of or designed for.
- Unlabeled Data for training : Unlike classical models that typically work well when trained on labeled data, Generative models can learn from unlabeled data. They are auto-regressive in nature. This approach lets them use vast datasets from the internet without hte need for costly and time consuming labeling processes. So, just by giving the huge data in the internet, libraries and universities, the models can be trained.
- Gen AI risks and limitations
- Bias and Fairness - Gen AI models can inherit biases present in the training data, leading to unfair or discriminatory outputs. This is particularly concerning in applications like hiring, lending, and law enforcement.
- Misinformation and Disinformation - The ability of Gen AI to generate realistic text and images can be exploited to create misleading or false information, contributing to the spread of misinformation and disinformation.
- Privacy Concerns - Gen AI models trained on large datasets may inadvertently expose sensitive or private information, raising concerns about data privacy and security.
- Environmental Impact - Training large Gen AI models requires significant computational resources, leading to high energy consumption and carbon emissions.
- Intellectual Property Issues - The use of copyrighted material in training datasets raises questions about ownership and intellectual property rights for generated content.
- Ethical Considerations - The potential for misuse of Gen AI technology, such as deepfakes or automated propaganda, raises ethical concerns about its impact on society.
Saturday 7-12-2025 - Building multi agentic system - Session 1 - Langchain Ecosystem - An Introduction
Presenter - Samrat Kar
Topics covered -
- What is an LLM based system?
- How is an LLM based system different from a traditional software system?
- What is context, and how this context is provided to the LLM - prompts, RAG, MCP
- The 8 steps involved in end to end working of an LLM to output result of a query. - training using corpus, Tokenization, Embedding, Vector DB creation & RAG, Query & Prompts, Search, Retrieval, Output.
- What is an agentic AI system?
- What is Lanchain? The elements of langchain - Prompts, LLM, chain, Vector Db, Index, Memory state, data loader, data splitter: https://www.youtube.com/watch?v=1bUy-1hGZpI&t=241s
- Tokenization via Byte Pair Encoding (BPE) - High level intro. Details for the exact algorithm can be found at - https://samratkar.github.io/2024/01/26/BPE.html
Session video recording
Langchain Ecosystem - An Intro - Session 1 - Video
Passcode - cA&ag%P0
Handwritten Notes
The Syllabus
Syllabus for building Multi Agent AI systems
Working Code
Sunday 6-22-2025 - GAN and general discussion
Presenter - Samrat Kar
Topics covered and notes -
- Papers review - https://substack.com/home/post/p-166488449
- GANs - https://samratkar.github.io/2025/03/09/GAN.html
- Handwritten notes
- A review of deep learning and neural network concepts.
- GAN paper - Generative Adversarial Networks
Session Video Recording
GAN - an Intro - Session 1 - Video
Passcode *=Qs!7nM
Saturday 6-21-2025 - Ensemble models and MCP
Presenter - Naman Aryan
Sunday 6-15-2025 - System Design for LLM based applications - Session 1
Presenter - Subhadeep Roy
Topics covered -
- LLMs can be self hosted or can be used as a service.
- When hosting LLMs there are various architectural choices that are done which takes care into engineering issues like -
- latency
- scalability
- cost
- availability
- thoroughput
- security
- LLMs typically need to be fine tuned for multiple use cases. That sets LLMs apart from traditional ML models. Traditional ML models solve one specific problem for which it is trained. But LLMs are trained for a wide range of problems and hence need to be fine tuned for specific use cases.
- RLHF - reinformcement leanring with human feedback is a technique used to fine tune LLMs. It is a way to make LLMs more aligned with human values and preferences.
- While hosting LLMs, it is important to host them in GPUs.
- H100 - most powerful GPU available in the market.
- Other GPUs like A100, V100, T4, L4 are also available in the market.
- Typically a cluster of GPUs, CPUs and SSDs are used, and different threads of parallel processing is run to process different pieces of jobs in parallel.
- VLLM, SGLang, Ray - These are the wrappers over LLMs that are used to optimize hosting and performance of LLMs.
- There are services like RunPod that can be used as GPU as a service at a minimal cost of $1/hour or so.
- Typically LLMs are huge matrices of weights and biases. These are implemented in safe tensors.
- To reduce latency of these LLMS typical strategies are
- quantization - reducing the precision of the weights and biases to reduce the size of the model.
- pruning - removing the weights and biases that are not used in the model.
- distillation - creating a smaller model that is trained on the outputs of the larger model.
- sharding - splitting the model into smaller pieces and distributing them across multiple GPUs.
- LLMs are typically hosted in a private cloud or a public cloud.
- In a private cloud, the LLMs are hosted in the corporate firewall and are accessible only to the employees of the company.
- In a public cloud, the LLMs are hosted in the public cloud and are accessible to anyone who has access to the internet.
- A typical system design of an LLM based system
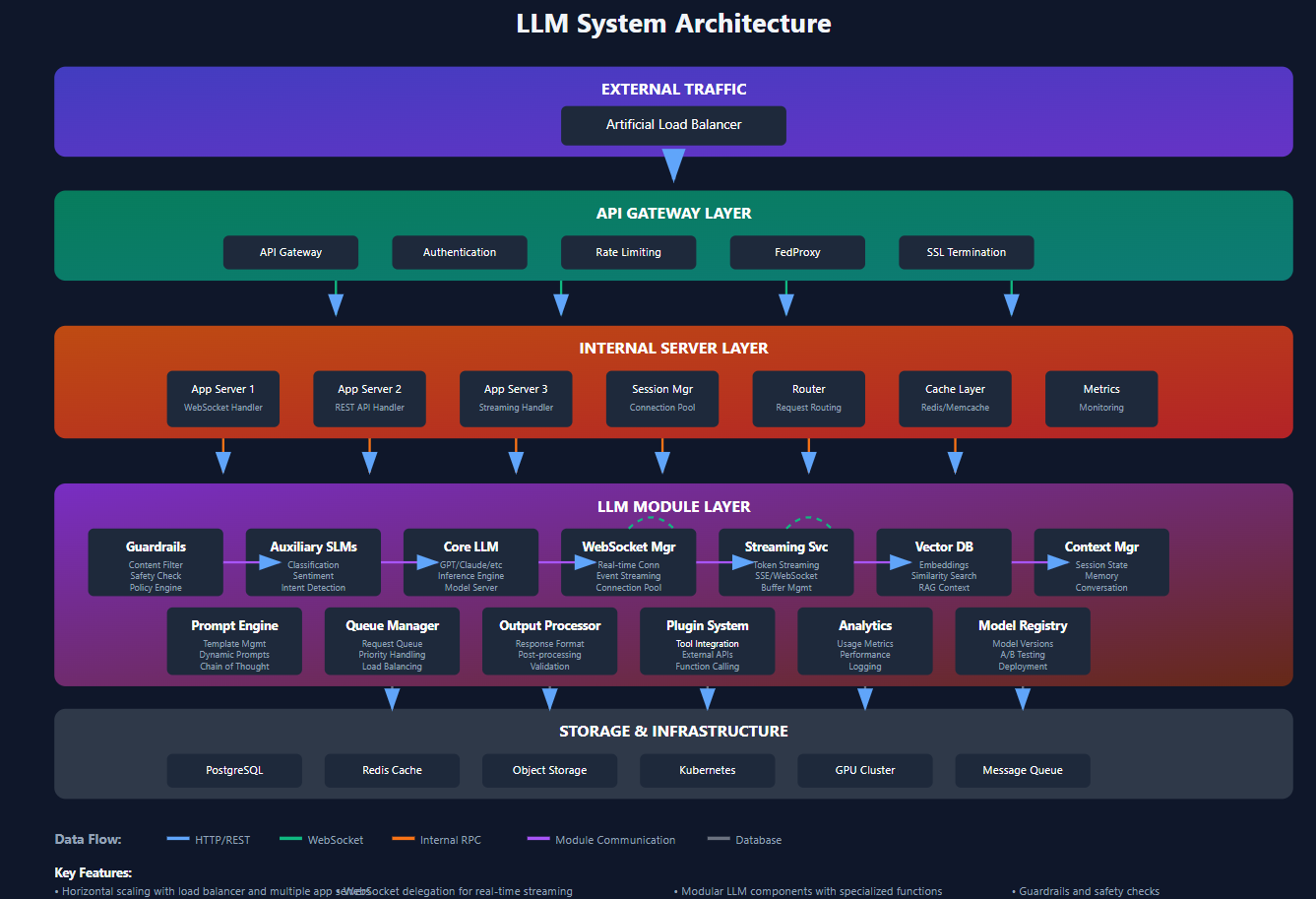
- Embeddings
- The corpus is divided into tokens and that is transformed to a higher dimensional space using embeddings.
- Embeddings are done done by neural network models that are known as embeddings models.
- Embedding models are trained on a large corpus of text and are used to convert the tokens into vectors in a higher dimensional space.
- The output of the embedding model is basically transformation of a token into a vector in a higher dimensional space.
- All tokens are converted into vectors in the same higher dimensional space. This helps preserving their meaning and context, based on their proximity to each other in the higher dimensional space.
This is the system architecture of training an embedding model and generation of vector db

Saturday 6-14-2025 - Introduction to LLM based applications
Handwritten notes
Topics covered -
- Evolution of deep learning to transformers - Attention mechanism - https://samratkar.github.io/2025/03/14/attention-overview.html
- shortcomings of LLMs and relevance of tool calling and agentic workflow
- LLMs are natural language processing tools that can predict next token probabilistically, based on the context provided.
- So, to be able to do a mathematical deterministic computation, LLM might not be the right tool.
- Hence we use LLM to choose different functions to call, based on the context provided and then use those functions to do the computation. Here we used best of both the worlds. LLM uses the docstrings and comments of the functions to determine which function to call. And the function does the actual computation.
- When multiple functions calling, also known as tool calling becomes complex, we use agentic workflow to manage the flow of function calls and responses.
- LLM typically does not have memory by itself. But modern LLMs have inbuilt memory capabilities which can be used to store the context of the conversation. This is useful for applications like chatbots where the context of the conversation needs to be maintained. You can see how the chatgpt application of your phone already knows about your hobbies, your friends, your profession, based on the conversations you had with it.
- Training LLMs - Fine tuning, context enhancement - difference between fine tuning and weight changes to just giving context during inference
- Training of LLMs technically means changing the weights of the model. This is a very expensive process and requires a lot of computational resources.
- You can do an instructional fine tuning, where you can supply questions and answers and train the model with that and update the weights. This will enable the LLM to be able to answer those questions in the future. This is a way to make domain specific LLMs.
- However, this is not the only way to make LLMs domain specific. You can also provide context during inference time, which is much cheaper and faster. This is called context enhancement. You can provide the context in the form of a document or a set of documents that the LLM can refer to while generating the response. This is useful for applications like chatbots where you want the LLM to be able to answer questions based on the context provided.
- Unsupervised Fine Tuning : Anthropic introduces a new unsupervised algorithm, Internal Coherence Maximization (ICM), to fine-tune pretrained language models on their own generated labels. It matches human supervision.
Anthropic teaches LLMs to fine tune themselves!
Research paper - https://arxiv.org/pdf/2506.10139
##### Audio summary from NotebookLM -
- privacy concerns - dataiku, guardrails, SLAs, azure open ai vs openai APIs, high level overview on how security is implemented on a corporate context.
- In a corporate context, the LLMs are deployed in the private cloud subscriptions inside the corporate firewall. This is done to ensure that the data is not exposed to the public cloud and is secure.
- In the LLM pipeline, tools like Dataiku are used to manage the data and the LLMs. Dataiku is a data science platform that provides tools for data preparation, model training, and deployment. It also provides tools for monitoring and managing the LLMs in production. So, the queries are first passed into Dataiku which does the sanity check using the Guardrails and then passes the query to the LLM.
- Overview of LLMOps and how it enables an ongoing continuous improvement of the LLM based applications.
- LLMOPs is a pipeline that is set up to do the entire end to management of the LLM, from taking a foundation model, to fine tune it, to deploying it, to monitoring it, to retraining it, to updating it, to scaling it, to managing the costs.
- LLMOPs Details
- Introduction to abstraction layers between LLM and LLM based apps to facilitate ease of change of LLMs. - using libraries like langchain, langgraph, llama-index
- Introduction to MCP and how that facilitates easier context injection to LLM making LLM aware of realtime contexts on which it was not trained to start with
- Introduction to SLM and how it can help in building a no-trust ecosystem
Sunday 6-6-2025 - Introduction to AI and ML
Today’s topics covered -
- Deep learning - backward propagation intuition
- Improvements on deep learning - RNN and LSTM high level overview
- Attention mechanism and transformer architecture overview
- Position embeddings, Attention scores
- RL overview
- Value alignment overview
- Limitation of LLM and need for multi agentic systems
- Introduction to langchain and llama index and how it helps build multi agentic systems
Notes
- Attention is all you need paper - https://arxiv.org/abs/1706.03762
- RNN - https://samratkar.github.io/2025/02/01/RNN-theo.html
- LSTM - https://samratkar.github.io/2025/02/15/LSTM-theory.html
- Position embedding - https://samratkar.github.io/2025/03/11/position-embed.html
- Attention mechanism - https://samratkar.github.io/2025/03/14/attention-overview.html
- Gradient Descent - https://www.youtube.com/watch?v=jl5LjHyrgBg&t=310s
Courses -
- Jay Alammar Course on Attention mechanism - https://learn.deeplearning.ai/courses/how-transformer-llms-work/lesson/nfshb/introduction
- Joshua Starmer’s Course on Attention mechanism - https://learn.deeplearning.ai/courses/attention-in-transformers-concepts-and-code-in-pytorch/lesson/han2t/introduction
Books -
Book to buy to understand the internals of attention mechanism - Hands-On Large Language Models by Jay Alammar - https://www.shroffpublishers.com/books/9789355425522/
Youtube channels to subscribe for attention mechanism internals -
- https://www.youtube.com/@vizuara - Vizuara by Raj Dandekar
- https://www.youtube.com/@SebastianRaschka - Sebastian Raschka
- https://www.youtube.com/@arp_ai - Jay Alammar
- https://www.youtube.com/@statquest - Joshua Starmer
Youtube channel to subscribe for LLM based app development
- Krish Naik - https://www.youtube.com/@krishnaik06